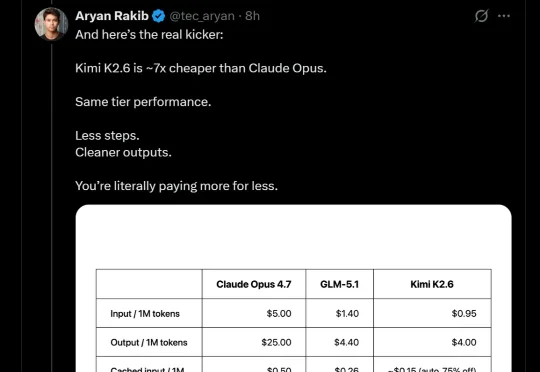
国产大模型杀疯了!一手横测 MiniMax、DeepSeek V4、Kimi K2.6、MiMo 后,我找到了最能干活的 AI 牛马
国产大模型杀疯了!一手横测 MiniMax、DeepSeek V4、Kimi K2.6、MiMo 后,我找到了最能干活的 AI 牛马从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。
来自主题: AI产品测评
10400 点击 2026-05-02 11:01